
STM32 besitzt je nach Chipvariante eine serielle Audio-Schnittstelle SAI. Durch diese Schnittstelle kann über übliche Protokolle mit Audio-Codecs kommuniziert werden.
Audio-Clocks
Das Codec und die SAI-Schnittstelle müssen synchronisiert werden. Dabei gibt es konkrete Vorgaben bzw. Randbedingungen seitens Codecs.
- Audio-Abtastfrequenz
 wählen.
wählen. - Den Multiplikator
 (Codecs haben oft Multiplikatortabellen z.B. 256 oder 512 bei 48kHz) wählen.
(Codecs haben oft Multiplikatortabellen z.B. 256 oder 512 bei 48kHz) wählen. - Daraus die erforderliche Master-Clock-Frequenz berechnen. (Oft
 )
) - Master-Clock-Quelle konfigurieren (Externer Quarz bzw. interne Clockquellen)
Übertragung
Unter dem Aspekt gibt es (wie für viele andere Hardwarekomponenten) hauptsächlich drei Möglichkeiten eine Codec-Schnittstelle zu steuern bzw. auszulesen:
- Normaler Modus (Blockierend)
- Interrupt-Modus (Nicht-blockierend)
- Per DMA auslesen (Nicht-blockierend)
Bei einer echtzeitkritischen Audio-DSP-Anwendung kommt nur DMA-Schnittstelle in Frage. Die Konfiguration der Software und Hardware ist hier beschrieben.
SAI und DMA Konfiguration
Beim Flex 500 ist feste 48kHz Abtastrate gewählt. Bei CS4272 kann der Multiplikator 256 oder 512 gewählt werden. Um auch zukünftig 96kHz zu unterstützen wurde hierbei 512 gewählt. Zu Stabilitätszwecken wurde für einen externen Quarz entschieden. Die Frequenz des Quarzes berechnet sich also als
(1) 
In dem Fall ist der Codec der Master und generiert den Bitclock. Der DSP ist Slave und erhält den Bitclock und dazugehörige Streams.
Die Konfiguration sieht folgendermaßen aus:
Low level Treiber: (*_hal_msp.c)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 |
void HAL_SAI_MspInit(SAI_HandleTypeDef* hsai) { GPIO_InitTypeDef GPIO_InitStruct; /* SAI1 */ if(hsai->Instance==SAI1_Block_A) { /* Peripheral clock enable */ if (SAI1_client == 0) { __HAL_RCC_SAI1_CLK_ENABLE(); } SAI1_client ++; /**SAI1_A_Block_A GPIO Configuration PE4 ------> SAI1_FS_A PE5 ------> SAI1_SCK_A PE6 ------> SAI1_SD_A */ GPIO_InitStruct.Pin = GPIO_PIN_4|GPIO_PIN_5|GPIO_PIN_6; GPIO_InitStruct.Mode = GPIO_MODE_AF_PP; GPIO_InitStruct.Pull = GPIO_NOPULL; GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_LOW; GPIO_InitStruct.Alternate = GPIO_AF6_SAI1; HAL_GPIO_Init(GPIOE, &GPIO_InitStruct); /* Peripheral DMA init*/ /* DMA controller clock enable */ __HAL_RCC_DMA2_CLK_ENABLE(); hdma_sai1_a.Instance = DMA2_Stream1; hdma_sai1_a.Init.Request = DMA_REQUEST_SAI1_A; hdma_sai1_a.Init.Direction = DMA_PERIPH_TO_MEMORY; hdma_sai1_a.Init.PeriphInc = DMA_PINC_DISABLE; hdma_sai1_a.Init.MemInc = DMA_MINC_ENABLE; hdma_sai1_a.Init.PeriphDataAlignment = DMA_PDATAALIGN_WORD; hdma_sai1_a.Init.MemDataAlignment = DMA_MDATAALIGN_WORD; hdma_sai1_a.Init.Mode = DMA_CIRCULAR; hdma_sai1_a.Init.Priority = DMA_PRIORITY_HIGH; hdma_sai1_a.Init.FIFOMode = DMA_FIFOMODE_DISABLE; // hdma_sai1_a.Init.FIFOThreshold = DMA_FIFO_THRESHOLD_HALFFULL; // hdma_sai1_a.Init.MemBurst = DMA_MBURST_SINGLE; // hdma_sai1_a.Init.PeriphBurst = DMA_PBURST_SINGLE; if (HAL_DMA_Init(&hdma_sai1_a) != HAL_OK) { // _Error_Handler(__FILE__, __LINE__); } /* DMA2_Stream1_IRQn interrupt configuration */ HAL_NVIC_SetPriority(DMA2_Stream1_IRQn, 1, 0); HAL_NVIC_EnableIRQ(DMA2_Stream1_IRQn); /* Several peripheral DMA handle pointers point to the same DMA handle. Be aware that there is only one channel to perform all the requested DMAs. */ __HAL_LINKDMA(hsai,hdmarx,hdma_sai1_a); __HAL_LINKDMA(hsai,hdmatx,hdma_sai1_a); } if(hsai->Instance==SAI1_Block_B) { /* Peripheral clock enable */ if (SAI1_client == 0) { __HAL_RCC_SAI1_CLK_ENABLE(); } SAI1_client ++; /**SAI1_B_Block_B GPIO Configuration PE3 ------> SAI1_SD_B */ GPIO_InitStruct.Pin = GPIO_PIN_3; GPIO_InitStruct.Mode = GPIO_MODE_AF_PP; GPIO_InitStruct.Pull = GPIO_NOPULL; GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_LOW; GPIO_InitStruct.Alternate = GPIO_AF6_SAI1; HAL_GPIO_Init(GPIOE, &GPIO_InitStruct); /* Peripheral DMA init*/ hdma_sai1_b.Instance = DMA2_Stream0; hdma_sai1_b.Init.Request = DMA_REQUEST_SAI1_B; hdma_sai1_b.Init.Direction = DMA_MEMORY_TO_PERIPH; hdma_sai1_b.Init.PeriphInc = DMA_PINC_DISABLE; hdma_sai1_b.Init.MemInc = DMA_MINC_ENABLE; hdma_sai1_b.Init.PeriphDataAlignment = DMA_PDATAALIGN_WORD; hdma_sai1_b.Init.MemDataAlignment = DMA_MDATAALIGN_WORD; hdma_sai1_b.Init.Mode = DMA_CIRCULAR; hdma_sai1_b.Init.Priority = DMA_PRIORITY_HIGH; hdma_sai1_b.Init.FIFOMode = DMA_FIFOMODE_DISABLE; // hdma_sai1_b.Init.FIFOThreshold = DMA_FIFO_THRESHOLD_HALFFULL; // hdma_sai1_b.Init.MemBurst = DMA_MBURST_SINGLE; // hdma_sai1_b.Init.PeriphBurst = DMA_PBURST_SINGLE; if (HAL_DMA_Init(&hdma_sai1_b) != HAL_OK) { // _Error_Handler(__FILE__, __LINE__); } /* DMA interrupt init */ /* DMA2_Stream0_IRQn interrupt configuration */ HAL_NVIC_SetPriority(DMA2_Stream0_IRQn, 1, 0); HAL_NVIC_EnableIRQ(DMA2_Stream0_IRQn); /* Several peripheral DMA handle pointers point to the same DMA handle. Be aware that there is only one channel to perform all the requested DMAs. */ __HAL_LINKDMA(hsai,hdmarx,hdma_sai1_b); __HAL_LINKDMA(hsai,hdmatx,hdma_sai1_b); } } |
SAI Konfiguration
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
void c_sai::MX_SAI1_Init(void) { hsai_BlockA1.Instance = SAI1_Block_A; hsai_BlockA1.Init.AudioMode = SAI_MODESLAVE_RX; hsai_BlockA1.Init.Synchro = SAI_ASYNCHRONOUS; hsai_BlockA1.Init.OutputDrive = SAI_OUTPUTDRIVE_DISABLE; hsai_BlockA1.Init.FIFOThreshold = SAI_FIFOTHRESHOLD_EMPTY; hsai_BlockA1.Init.AudioFrequency = SAI_AUDIO_FREQUENCY_48K; hsai_BlockA1.Init.SynchroExt = SAI_SYNCEXT_OUTBLOCKA_ENABLE; hsai_BlockA1.Init.MonoStereoMode = SAI_STEREOMODE; hsai_BlockA1.Init.CompandingMode = SAI_NOCOMPANDING; hsai_BlockA1.Init.TriState = SAI_OUTPUT_NOTRELEASED; if (HAL_SAI_InitProtocol(&hsai_BlockA1, SAI_I2S_STANDARD, SAI_PROTOCOL_DATASIZE_32BIT, 2) != HAL_OK) { // _Error_Handler(__FILE__, __LINE__); } hsai_BlockB1.Instance = SAI1_Block_B; hsai_BlockB1.Init.AudioMode = SAI_MODESLAVE_TX; hsai_BlockB1.Init.Synchro = SAI_SYNCHRONOUS; hsai_BlockB1.Init.OutputDrive = SAI_OUTPUTDRIVE_DISABLE; hsai_BlockB1.Init.FIFOThreshold = SAI_FIFOTHRESHOLD_EMPTY; hsai_BlockB1.Init.SynchroExt = SAI_SYNCEXT_DISABLE; hsai_BlockB1.Init.MonoStereoMode = SAI_STEREOMODE; hsai_BlockB1.Init.CompandingMode = SAI_NOCOMPANDING; hsai_BlockB1.Init.TriState = SAI_OUTPUT_NOTRELEASED; if (HAL_SAI_InitProtocol(&hsai_BlockB1, SAI_I2S_STANDARD, SAI_PROTOCOL_DATASIZE_32BIT, 2) != HAL_OK) { // _Error_Handler(__FILE__, __LINE__); } } |
Starten vom Treiber
|
1 2 3 4 5 6 7 8 9 10 11 12 |
void c_sai::start(void){ //Start SAI and DMA Streams printf("Initializing SAI DMA Receive stream...\n"); // printf("Initializing SAI DMA Receive stream...\n"); HAL_SAI_Receive_DMA(&hsai_BlockA1, (uint8_t*)&rx_buf, 4*buf_size); printf("SAI DMA Receive stream initialized!\n"); // printf("Initializing SAI DMA transmit stream...\n"); HAL_SAI_Transmit_DMA(&hsai_BlockB1, (uint8_t*)&tx_buf, 4*buf_size); printf("SAI DMA transmit stream initialized!\n"); } |
DMA Interrupts setzen die Flags. Die Software Architektur ist hier beschrieben.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
void HAL_SAI_TxCpltCallback(SAI_HandleTypeDef *hsai) { tx_status=0; } void HAL_SAI_TxHalfCpltCallback(SAI_HandleTypeDef *hsai){ tx_status=1; } void HAL_SAI_RxCpltCallback(SAI_HandleTypeDef *hsai){ rx_status=0; } void HAL_SAI_RxHalfCpltCallback(SAI_HandleTypeDef *hsai){ rx_status=1; } |
Die CODEC-Treiber sind hier beschrieben:
CS4272 CODEC-Schnittstelle für Nucleo H743
WM8731 CODEC-Schnittstelle für Nucleo H743
Ressourcen
Der vollständige Code vom Communication Stack befindet sich auf den Repositories vom Controller und DSP unter den Ordnern „hw„.



 = 48kHz
= 48kHz

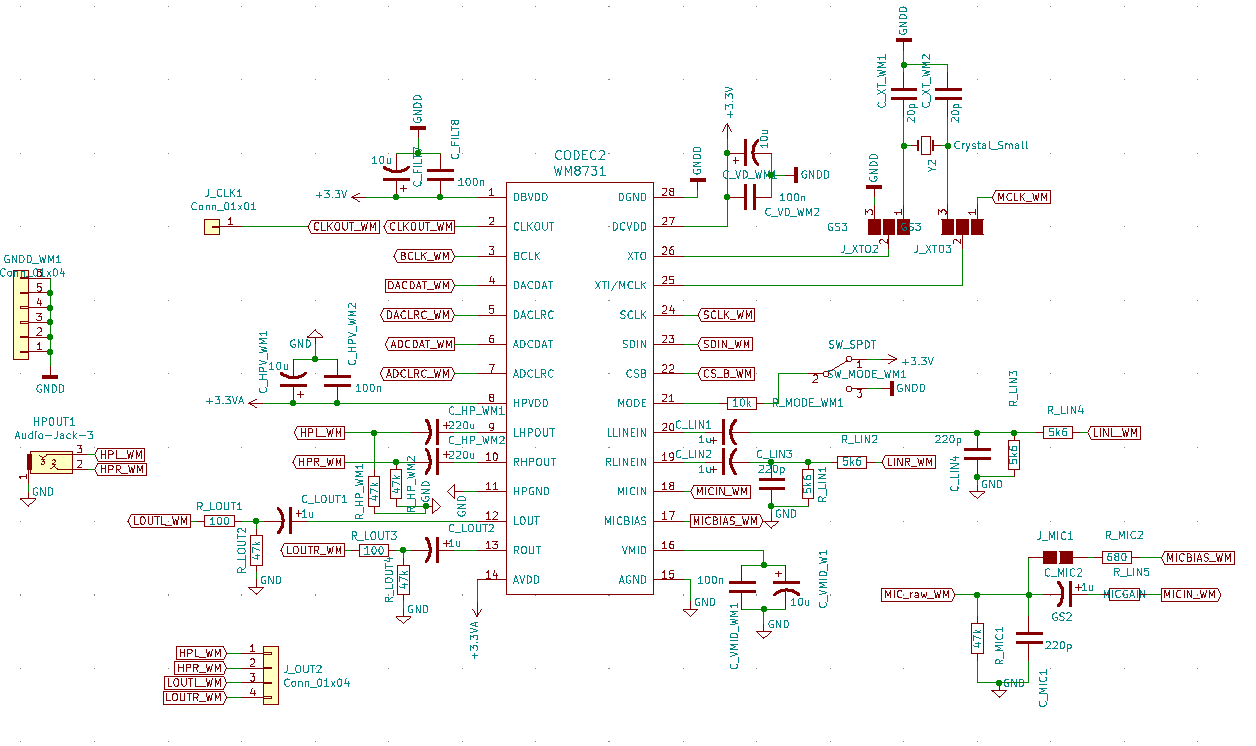


 hat. Für die symmetrischen Eingänge muss das Signal vom Preamp-Board in einen Pegel von
hat. Für die symmetrischen Eingänge muss das Signal vom Preamp-Board in einen Pegel von  gebracht werden. Danach muss eine Gleichspannung
gebracht werden. Danach muss eine Gleichspannung  addiert werden, damit das Eingangssignal in den erlaubten Bereich vom CS4272
addiert werden, damit das Eingangssignal in den erlaubten Bereich vom CS4272  gebracht werden. Das wird in der untenstehenden Schaltung realisiert:
gebracht werden. Das wird in der untenstehenden Schaltung realisiert:
 auf die durch die Kondensatoren C_INAx entkoppelte Eingangsspannung addiert und ein Eingangspuffer hinzugefügt.
auf die durch die Kondensatoren C_INAx entkoppelte Eingangsspannung addiert und ein Eingangspuffer hinzugefügt.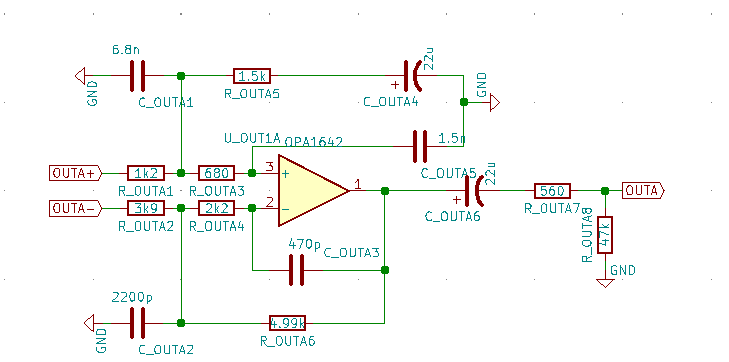
 und
und  in einer Stufe voneinander abgezogen. Danach wird mit dem Ausgangskondesator C_OUTA6 der Gleichstrom herausgefiltert. Schließlich arbeitet die ganze Schaltung auf einen Lastwiderstand von
in einer Stufe voneinander abgezogen. Danach wird mit dem Ausgangskondesator C_OUTA6 der Gleichstrom herausgefiltert. Schließlich arbeitet die ganze Schaltung auf einen Lastwiderstand von  . Hierbei handelt es sich um das Referenz Design von CS4272.
. Hierbei handelt es sich um das Referenz Design von CS4272.

 der Threshold-Wert ist, ab dem das Clipping erfolgt.
der Threshold-Wert ist, ab dem das Clipping erfolgt. ) ist sogar schädlich für die Lautsprecher (wobei der üblicherweise von der Leistungselektronik herausgefiltert wird)
) ist sogar schädlich für die Lautsprecher (wobei der üblicherweise von der Leistungselektronik herausgefiltert wird)![\begin{equation*} y=sgn(x) [1-e^{-k x sgn(x)}] \end{equation*}](https://www.cankosar.com/wp-content/ql-cache/quicklatex.com-3cf938dc305a9115affb7a41f81c9801_l3.png "Rendered by QuickLaTeX.com")

 als Vorverstärkung gesehen werden kann.
als Vorverstärkung gesehen werden kann. und
und  dargestellt.
dargestellt.

 beschreibt die Kompressionsrate, mit der das Signal abgeschwächt wird. Dies greift ab dem Überschreiten eines Threshold-Werts.
beschreibt die Kompressionsrate, mit der das Signal abgeschwächt wird. Dies greift ab dem Überschreiten eines Threshold-Werts.

 ergibt. Jeder Mensch empfindet die Lautstärke anders. Mann kann den Logarithmus auf 2 Basis, 10 Basis oder natürlichen Logarithmus nehmen.
ergibt. Jeder Mensch empfindet die Lautstärke anders. Mann kann den Logarithmus auf 2 Basis, 10 Basis oder natürlichen Logarithmus nehmen.