Die Frequenzerkennung (engl. Pitch detection, frequency detection) ist ein Prozess, mit dem man die dominantesten Frequenzen eines Audio-Abschnitts berechnet. Hierbei muss betont werden, dass ein Audio-Abschnitt nicht eine einzige Schwingung mit einer Frequenz besitzt. Er ist vielmehr eine Zusammensetzung von vielen Grundschwingungen, die sich zu jedem Zeitpunkt ändert. Wir nehmen z.B. die Gitarre: Wenn wir eine Saite zupfen, entstehen mehrere harmonische Grundschwingungen und ein paar nicht-harmonische Störschwingungen, die der Natur des Instruments geschuldet sind. Wir hören quasi ein „Bouqet“ aus Grundschwingungen. Wir als Menschen, nehmen deuten (zumindest oft) die dominanteste Schwingung als Grundfrequenz wahr. Die Aufgabe ist nun also diese Grundfrequenzen herauszufinden. Das ist eine sehr heikle Aufgabe, weil
- die Amplituden der dominantesten Schwingungen sich kontinuierlich ändern
- die dominanteste Schwingung sich im Laufe des Sample-Abschnitts ändern kann, (obwohl der ganze Sample auf eine Note deuten kann)
Die Anforderungen an einen Tuner können folgendermaßen zusammengefasst werden:
- Aktualisierungsrate >

- Minimale Frequenz:

- Maximale Frequenz=

- Messgenauigkeit:=

- Effiziente Berechnung (abhängig vom eingesetzten DSP)
Mathematische Ansätze
Es gibt verschiedene mathematische Ansätze für die Umsetzung der Frequenzbestimmung:
- Fourier-Transformation
- Hartley-Transformation
- Auto-Correlation
- …
Die Fourier und Hartley-Transformationen basieren auf den Ansatz, dass man das Signal erst in Frequenzbereich transformiert und das Frequenzspektrum ermittelt. Für niedrige Frequenzen kann das eine geeignete Methode sein, um 1 Cent Genauigkeit zu erreichen. Allerdings wird die Transformation sehr langsam, wenn wir das Spektrum über mehrere 100Hz mit Hundertstel-Hertz-Genauigkeit ermitteln wollen. Denn die Genauigkeit der Fourier-Transformation müssen wir über das ganze Spektrum festlegen. Anders bei der Auto-Korrelation:
Auto Korrelation
Das Prinzip der Auto-Korrelation (Selbst-Übereinstimmung) ist relativ einfach. Wir multiplizieren unser Signal mit sich selbst mit einem zeitlichen Offset. Danach erhalten wir einen skalaren Wert. Dieser Wert gibt uns eine quantitative Aussage darüber, wie das Signal bei diesem Offset mit sich selbst übereinstimmt. Wenn wir dann die Offsets finden, bei denen die Korrelation am Höchsten ist, können wir daraus die Frequenzen ermitteln. Die Frequenz wäre dann einfach der Kehrwert vom Offset.
Der Algorithmus sieht folgendermaßen aus:
(1) 
oder wenn das Signal im Puffer vorliegt, auch vorwärts berechnend:
(2) 
Dann erhalten wir einen Auto-Korrelationswert  für das Offset
für das Offset  . Die Anzahl der Samples
. Die Anzahl der Samples  , über die wir diesen Wert berechnen muss
, über die wir diesen Wert berechnen muss
- so groß wie möglich sein, um niedrige Frequenzen abbilden zu können und
- so klein wie möglich sein, um die Anzahl der Multiplikationen zu reduzieren.
Wenn wir bei der Messung von  eine Genauigkeit von 1 cent haben wollen, bedeutet das eine Frequenzgenauigkeit
eine Genauigkeit von 1 cent haben wollen, bedeutet das eine Frequenzgenauigkeit 
(3) 
Auf der anderen Seite, wenn wir tiefe Frequenzen gut auflösen wollen, brauchen wir einen Sampleabschnitt, der ein paar volle Schwingungen beinhaltet. Bei 4 mal 20Hz Schwingungen ergibt sich eine Sample-Anzahl von
(4) 
Also wenn wir den ganzen Frequenzbereich mit 0,3Hz Genauigkeit scannen und daraus die Autokorrelation von allen Frequenzen mit 9600 Samples berechnen, beträgt der Rechenaufwand
(5) ![\begin{equation*} O_{MAC}=[(440-27,5)/0.28] 6981=10284508 \end{equation*}](https://www.cankosar.com/wp-content/ql-cache/quicklatex.com-4fa190bfb38f5c7f224947368cefd6af_l3.png "Rendered by QuickLaTeX.com")
Multiplikation und Additionen. Das bedeutet rund 10,2Mio. Operationen pro Scan. Bei einer Aktualisierungsrate von  brauchen wir 200Mio. Rechenoperationen pro Scan – nur um Autokorrelationswerte zu berechnen. Also dieser primitiver Ansatz ist nicht geeignet, um die Frequenz auf eine effiziente Weise zu berechnen.
brauchen wir 200Mio. Rechenoperationen pro Scan – nur um Autokorrelationswerte zu berechnen. Also dieser primitiver Ansatz ist nicht geeignet, um die Frequenz auf eine effiziente Weise zu berechnen.
Ein effizienter Ansatz zur Frequenzbestimmung
Wenn wir nur an ein paar dominanten Frequenzen interessiert sind, müssen wir nicht die Auto-Korrelationswerte für das ganze Spektrum mit feiner Auflösung berechnen. Daraus entstehen einige Optimierungsansätze: Man kann erst den groben Bereich der dominanten Frequenzen berechnen und dann diese in dem Bereich suchen. Dieser Ansatz ist im unteren Diagramm dargestellt.

Die einzelnen Schritte dieses Ansatzes ist im Folgenden erklärt.
Das Spektrum RASTERN
Zuerst wollen wir das Spektrum zwischen A0 und A4, also 27,5Hz und 440Hz in so wenig wie möglich Raster teilen, bei denen wir uns sicher sind, dass nicht mehrere dominante Frequenzen drin vorkommen können. Im vorliegenden Fall möchten wir die dominante Frequenz eines Musikinstruments, konkreter Gitarre und Bassgitarre ermitteln. Für den Zweck bietet es sich an, die chromatischen Notenfrequenzen als Raster zu nehmen. Unten sind die Noten von 27,5Hz bis 440 Hz dargestellt.
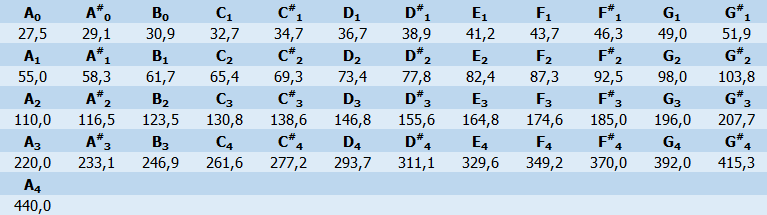
Notenfrequenzen
Das heißt, wir können das Spektrum, dass uns interessiert, erstmal in 49 Blöcke teilen. Dann berechnen wir nur den AC-Wert, der uns interessiert. Wir ermitteln hier die Information: „Um welche Note geht’s denn überhaupt?“
Zudem: Die Wahl der Noten nach chromatischen Frequenzen bei 440Hz-Stimmung, ist auch eine strategische Wahl. Denn: Die gefundenen Noten aus diesem Array werden genommen, um in ihrer Nähe nach der exakten Frequenz zu suchen. Diese Noten sind auch die erste Schätzung für die Suche. Mit der Annahme, dass dieser Algorithmus als chromatischer Tuner bei einem 440Hz-gestimmten Instrument benutzt werden soll, erwarten wir oft eine Übereinstimmung in unmittelbarer Nähe.
Zunächst werden diese Frequenzen als Offsets in einem Array gespeichert:
(6) 
Wir denken ab nun nicht mehr in Frequenzen  sondern in Offsets .
sondern in Offsets .
|
|
static const unsigned s_bins=49; unsigned note_bins[s_bins]={1745,1647,1555,1467,1385,... |
Erforderliche Sample-Anzahl für die Raster berechnen
Wie bereits erwähnt, brauchen wir bei tieferen Frequenzen mehr Samples für die Auto-Korrelation-Berechnung als bei höheren Frequenzen. Dafür muss man sich eine Art Güte ausdenken. Wenn man sich z.B. für eine Güte von 4 vornimmt, bedeutet das, dass man 4 volle Schwingungen einer Frequenz für die Auto-Korrelationsberechnung braucht. Das ergibt
(7) ![\begin{equation*} n(\delta)=[f_s/f] \psi \end{equation*}](https://www.cankosar.com/wp-content/ql-cache/quicklatex.com-566aee8c3a42ae4f5b83e42a22575f8d_l3.png "Rendered by QuickLaTeX.com")
bei der Güte  .
.
Die Implementierung würde folgendermaßen aussehen:
|
|
unsigned l_acbuf; unsigned l_max; //Length of samples we need l_acbuf=n_waves_ac*dist; l_max=bufsize-dist; if(l_acbuf>l_max){ l_acbuf=l_max; } |
Auto-Korrelationswert berechnen
Die Berechnung vom Auto-Korrelationswert ist oben beschrieben. Je nach Hardwareressourcen kann dies z.B. folgendermaßen implementiert werden.
|
|
ac_score=0; for(i=0;i<l_acbuf;i++){ ac_score+=buffer[i]*buffer[i+dist]; } |
Auto-Korrelationswert normieren
Wir haben variable Anzahl an Samples für jede Frequenz, da wir erstens tiefe Frequenzen erfassen können, andererseits bei höheren Frequenzen Ressourcen sparen wollen. Daraus ergeben sich Auto-Korrelationswerte, die nicht untereinander vergleichbar sind. Wir normieren diese deshalb nach der Länge der Samples, mit denen sie berechnet wurden. Damit kann man die Amplituden einzelner Raster miteinander vergleichen.
|
|
//Norming AC Score: Divide by the count of the samples ac_score=ac_score/l_acbuf; |
Extrema des Spektrums (PEAKS) ermitteln
Jetzt haben wir das Spektrum, d.h. die AC-Werte für jeden Rasterpunkt, ermittelt. Wir müssen nun dort herausfiltern, welche Offsets wir brauchen. Dieser Teil ist etwas „tricky“ und beruht auf folgenden Erfahrungswerten für Gitarren und Bass-Stimmung:
- Bei einer Einzelsaite entstehen u. a. zwei deutlich dominante Peaks.
- Die Peaks sind die ersten Harmonischen voneinander (
 )
)
- Die Amplituden der beiden Peaks sind sehr ähnlich und wechseln sich oft beim Ausklingen.
- Der tiefere Peak ist aussagekräftiger, da man dadurch die Frequenz (ohne Oversampling) präziser messen kann (n_2>n_1)
Deshalb versuchen wir im folgenden Schritt
- Zwei dominanteste Offsets (Peaks) aussuchen
- Diese sortieren
Das wird folgendermaßen implementiert.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
void c_tuner::find_peaks(void){ p1=0; p2=0; unsigned n_peak; //Peak count unsigned i; //Finding the peaks n_peak=0; //Number of found peaks for(i=1; i<s_bins-1;i++){ if(arr_ac[i]>0){ //Find only positive peaks if(arr_ac[i]>arr_ac[i-1] && arr_ac[i]>arr_ac[i+1]){ //Peak found // printf("Peak found:%f \t%f\n",(float)(FS/note_bins[i]),arr_ac[i]); n_peak++; //Number of found peaks if(n_peak==1){ //Check if the found peak is the first peak p1=i; //Initialize first peak (distance) }else if(n_peak==2){ //Check if the found peak is the second peak p2=i; //Initialize second peak (distance) } if(arr_ac[p1]<arr_ac[i]){ //If the current peak distance is greater than the last peak distance p2=p1; //Update the peak distances: Shift the next greatest to the second place p1=i; //Set the greatest }else if(arr_ac[p2]<arr_ac[i]){ //If the current peak distance is greater than the second peak distance p2=i; //Update the second peak } } } } } |
Nach den exakten Frequenzen (Offsets) suchen
Wir haben nun zwei Frequenzen ermittelt, bei denen wir wissen, unsere gesuchte Frequenz liegt in deren unmittelbare Nähe. Man kann sich das ungefähr folgendermaßen vorstellen:

Es existieren zahlreiche Suchalgorithmen. Je nach Anwendung können diese Vor- und Nachteile haben. Eine Übersicht ist hier verfügbar. In dem Fall bieten sich hauptsächlich zwei Suchalgorithmen
Die Wahl zwischen diesen Algorithmen sind im vorliegenden Fall schwierig. Wenn die gesuchte Frequenz in der Ferne liegt, ist binäre Suche vorteilhafter. Wenn diese aber in der Nähe liegt, ist lineare Suche vorteilhafter.
Die Implementierung dieser Suche ist folgendermaßen zu realisieren:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
unsigned c_tuner::get_exact_peak_linear(unsigned index){ unsigned dist=note_bins[index]; float ac_prev=calc_ac(dist-1); float ac=arr_ac[index]; float ac_next=calc_ac(dist+1); unsigned n=0; //Loop counter unsigned n_exit=100; //Emergency exit //Get gradient while(n<n_exit){ n++; if(ac>=ac_prev){ if(ac<ac_next){ //Gradient positive dist++; ac_prev=ac; ac=ac_next; ac_next=calc_ac(dist+1); }else if(ac>=ac_next){ //Found peak break; } }else if(ac<ac_prev){ //Gradient negative if(ac>=ac_next){ dist--; ac_next=ac; ac=ac_prev; ac_prev=calc_ac(dist-1); }else{ //Negative peak dist=0; break; } } } return dist; } |
Stochastische Abschätzung der GESUCHTEN Frequenz
Nachdem die exakten zwei Frequenzen ermittelt wurden, merkt man, dass dieser Wert in einem kleinen Intervall schwankt, was der Natur der Instrumente geschuldet ist. Nun muss
- die Plausibilität der berechneten Frequenzen bewertet und
- der Frequenzverlauf gemittelt werden,
damit der Benutzer eine vernünftige Frequenz- bzw. Notenanzeige hat. Dafür wird eine Toleranz  eingeführt, innerhalb dessen die Frequenz schwanken darf. Wenn eine Messung diese Toleranz überschreitet, vermutet man ein Notenwechsel. Also entweder wird eine andere Saite gezupft oder so stark korrigiert, dass man diese Messung nicht mehr in die Mittelung einfließen darf. Danach wird die Mittelung zurückgesetzt und weiterhin auf eine Messungfolge gewartet, wo alle Messungswerte innerhalb der Toleranz liegen. Danach wird die Note wieder gezeigt.
eingeführt, innerhalb dessen die Frequenz schwanken darf. Wenn eine Messung diese Toleranz überschreitet, vermutet man ein Notenwechsel. Also entweder wird eine andere Saite gezupft oder so stark korrigiert, dass man diese Messung nicht mehr in die Mittelung einfließen darf. Danach wird die Mittelung zurückgesetzt und weiterhin auf eine Messungfolge gewartet, wo alle Messungswerte innerhalb der Toleranz liegen. Danach wird die Note wieder gezeigt.
Die Implementierung kann folgendermaßen aussehen:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
/*This function uses methods of stochastics to estimate the frequency*/ void c_tuner::estimate_freq(void){ float ma; //Value of moving average float minimum, maximum; //Minimum and maximum values of one array double deviation; //Current deviation in the array float fin; fin=(float)FS/(float)p; //Input frequency //Moving average filter //Insert value buf_maf[maptr]=fin; //Update pointer maptr++; if(maptr>=l_maf){ maptr=0; } //Calculate moving average ma=0; minimum=buf_maf[0]; maximum=buf_maf[0]; unsigned i=0; for(i=0;i<l_maf;i++){ //Update moving average ma+=buf_maf[i]; //Find the minimum value of array if(buf_maf[i]<minimum){ minimum=buf_maf[i]; } //Find the minimum value of array if(buf_maf[i]>maximum){ maximum=buf_maf[i]; } } //Moving average value ma=ma/l_maf; //Deviation deviation=maximum/minimum; //Check if deviation is within the tolerance band if(deviation<=devtol){ //Note confidence good=>Everything fine last_conf_f=ma; // last_conf_t=HAL_GetTick(); //Commented out for Win fc=ma; }else{ //Note confidence bad => Set a timer // if((HAL_GetTick()-last_conf_t)<conf_timeout){ //Commented out for Win if(1){ fc=last_conf_f; }else{ //Timeout last_conf_f=0; last_conf_t=0; fc=0; } } printf("Fc=%.2f\n",fc); } |
Ressourcen
Hiermit wurde der Ablauf einer Frequenzermittlung für eine Tuner-Applikation gezeigt. Der vollständige Target-Code für DSP und der Simulationscode für Windows kann vom GitHub heruntergeladen werden.


 wählen.
wählen. (Codecs haben oft Multiplikatortabellen z.B. 256 oder 512 bei 48kHz) wählen.
(Codecs haben oft Multiplikatortabellen z.B. 256 oder 512 bei 48kHz) wählen. )
)















 (z.B. A4=440Hz) ändert, müssen die Schranken wieder berechnet werden, aber nicht in jedem Messzyklus.
(z.B. A4=440Hz) ändert, müssen die Schranken wieder berechnet werden, aber nicht in jedem Messzyklus.
